The BBC World Service archive prototype
Towards an alternative approach to publishing large archives?
Yves Raimond, BBC R&D IRFS / @moustaki
The BBC Archive
Cataloguing the archive
In Our Time archive
BBC Four Army collection
Tagging programmes
Linked Data
An alternative approach
The World Service archive
Unlocking the archive through machine listening
Automated speech recognition
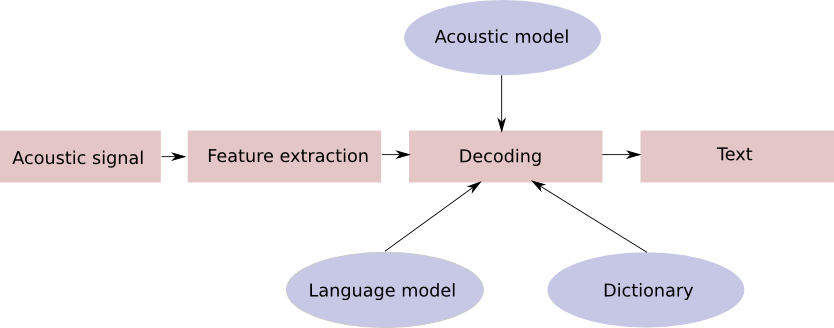
Automated transcripts
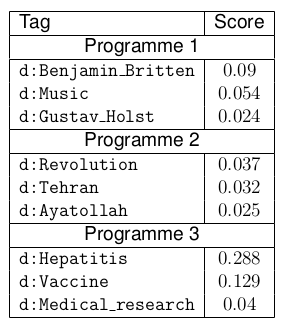
Automated tagging
Example results
Automated tagging evaluation
- Dataset of 132 programmes manually tagged
- TopN measure
- Random baseline: 0.0002
- Our algorithm: 0.209
- Next best: 0.195
- Dataset and evaluation script available on our Github
- Core algorithm available on Github
Processing archives in the cloud
Bootstrapping search and discovery
Noise
Data validation
Speaker segmentation
Crowd-sourcing speaker names
Propagating speaker names
Evaluating speaker identification
User activity
Emerging shape of the archive
Visualising the archive
http://worldservice.prototyping.bbc.co.uk
ClOud Marketplace for Multimedia Analysis
(COMMA)
Thank you!
Photo credits:
- http://www.flickr.com/photos/andyarmstrong/4402416306/
- http://www.flickr.com/photos/nicecupoftea/8579975238/
- http://www.flickr.com/photos/11561957@N06/5202870020/
- http://www.flickr.com/photos/hubmedia/2141860216/
- http://www.flickr.com/photos/allison_mcdonald/7604871594
- http://www.flickr.com/photos/aayars/4072755936/