Evaluation of the Music Ontology framework
Yves Raimond, BBC R&D
Mark Sandler, Queen Mary, University of London
Heraklion, Crete, Greece, 29 May 2012
Start by identifying your domain objects and the relationships between them
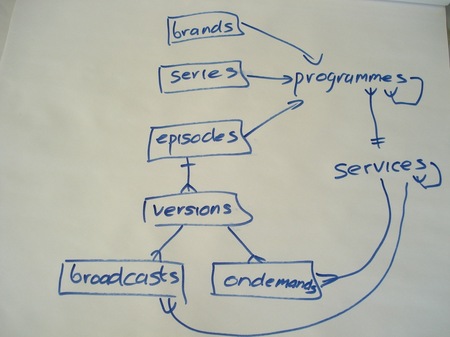
Ontologies are increasingly used to power bbc.co.uk
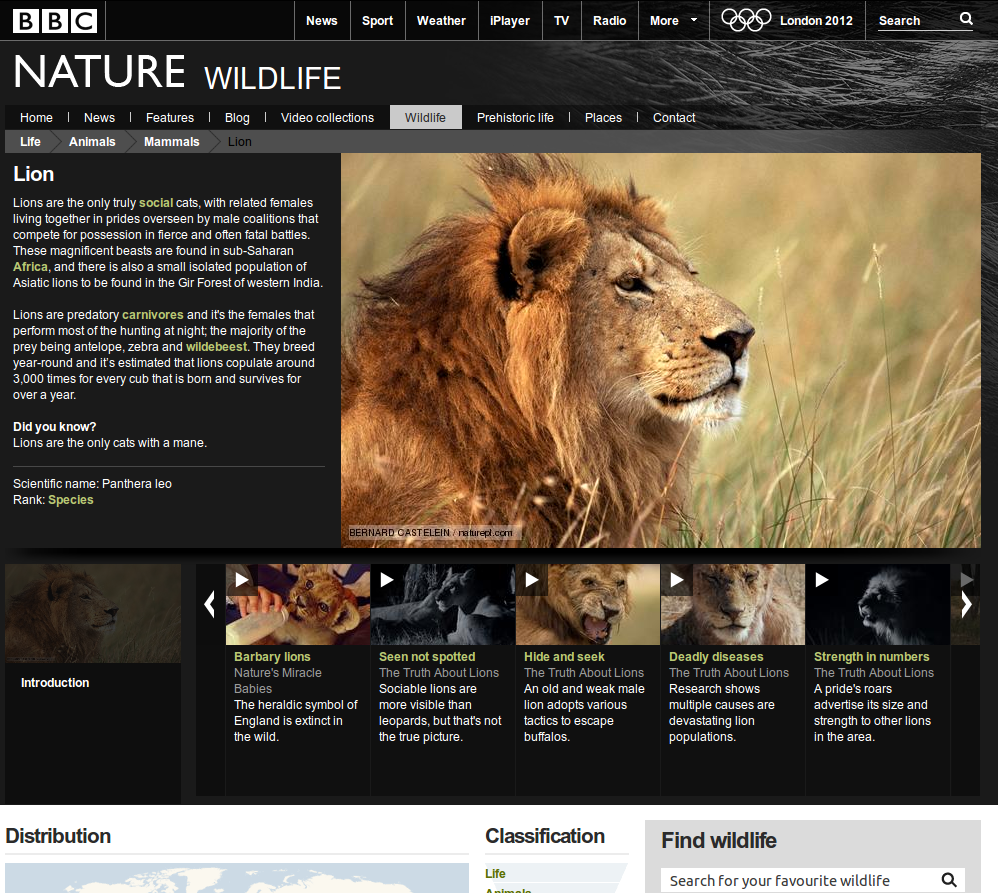
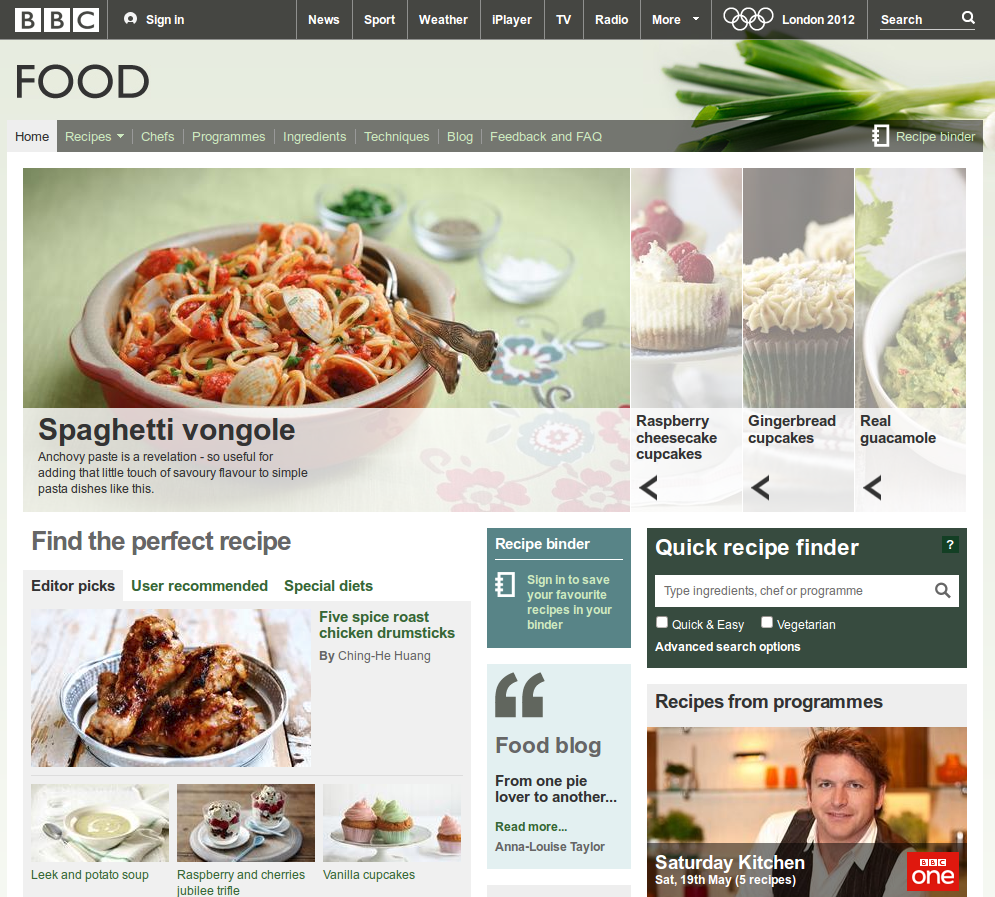
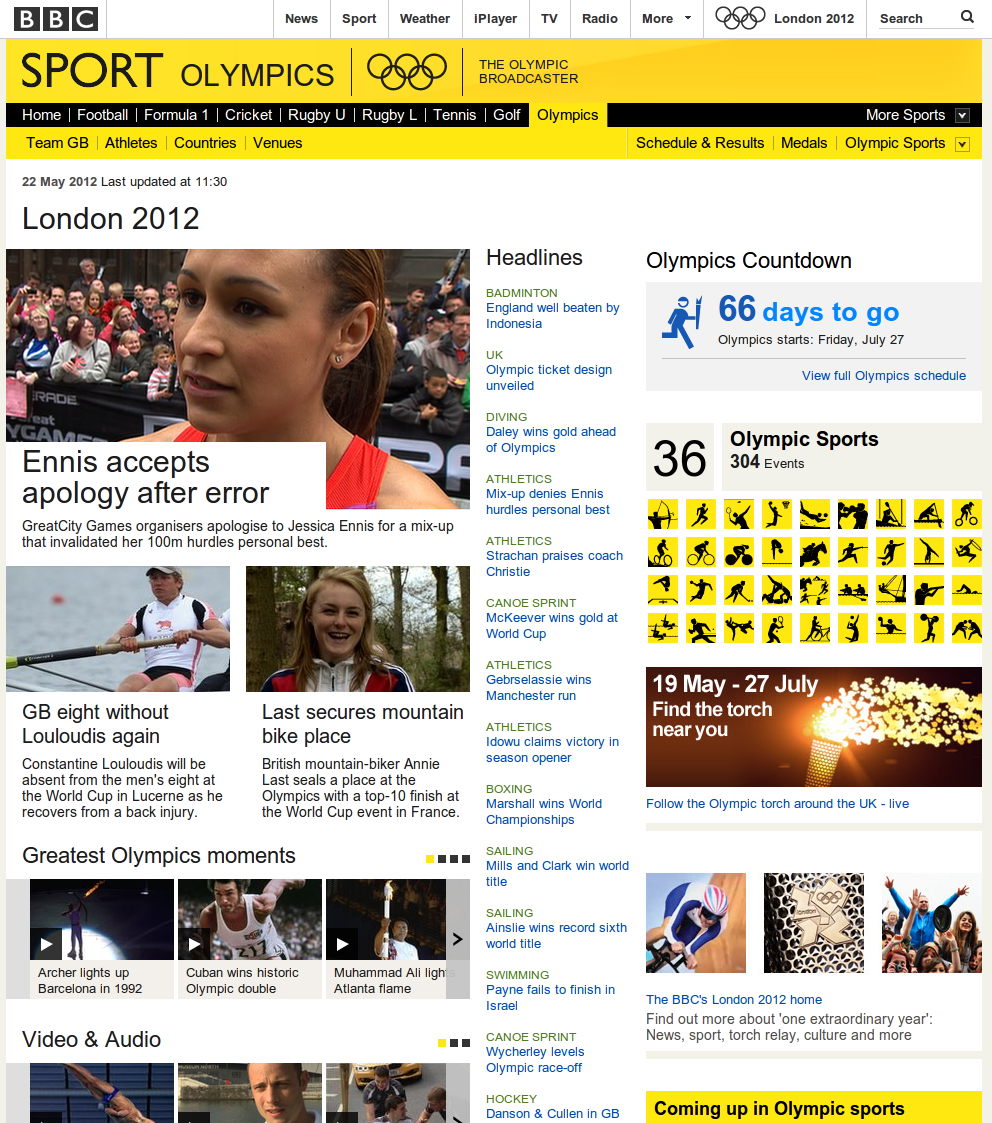
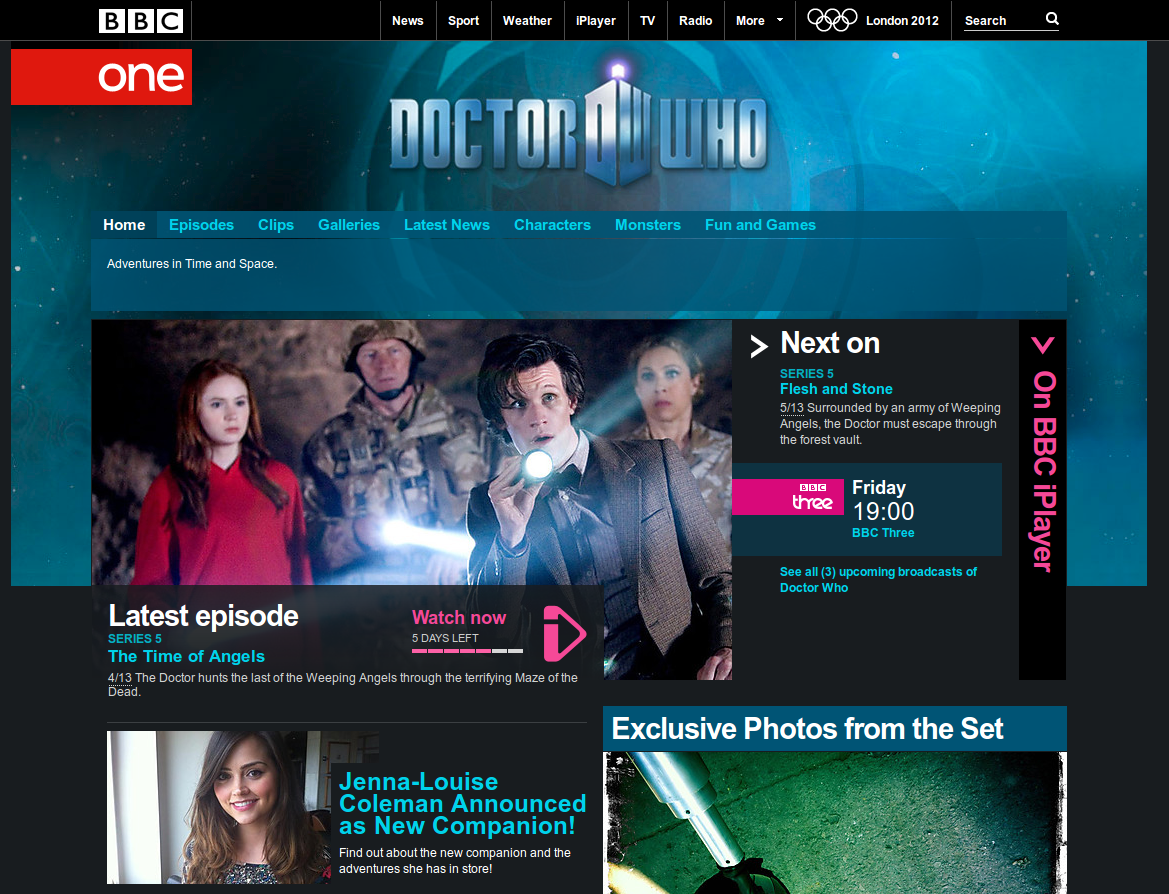
The Programme Ontology
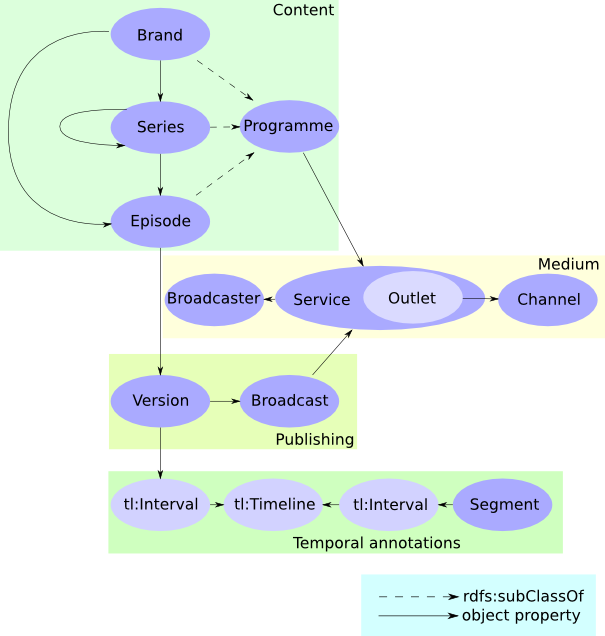
The Music Ontology
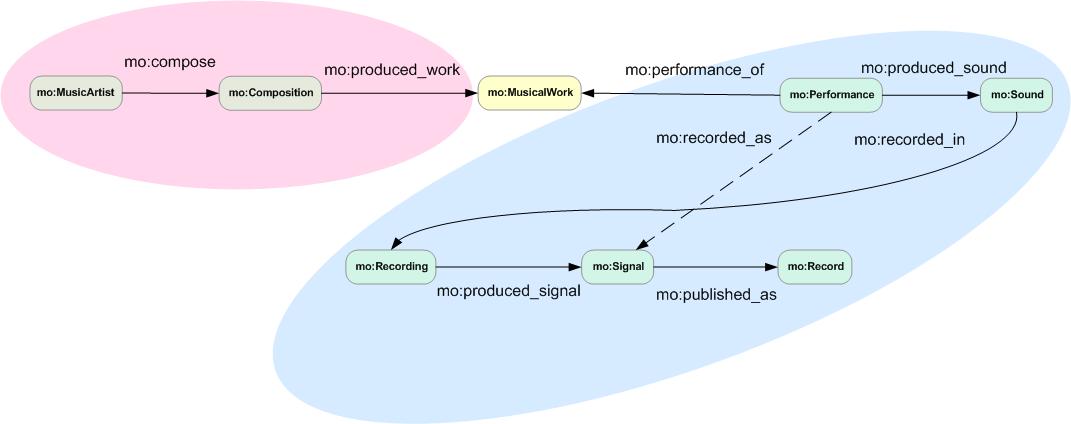
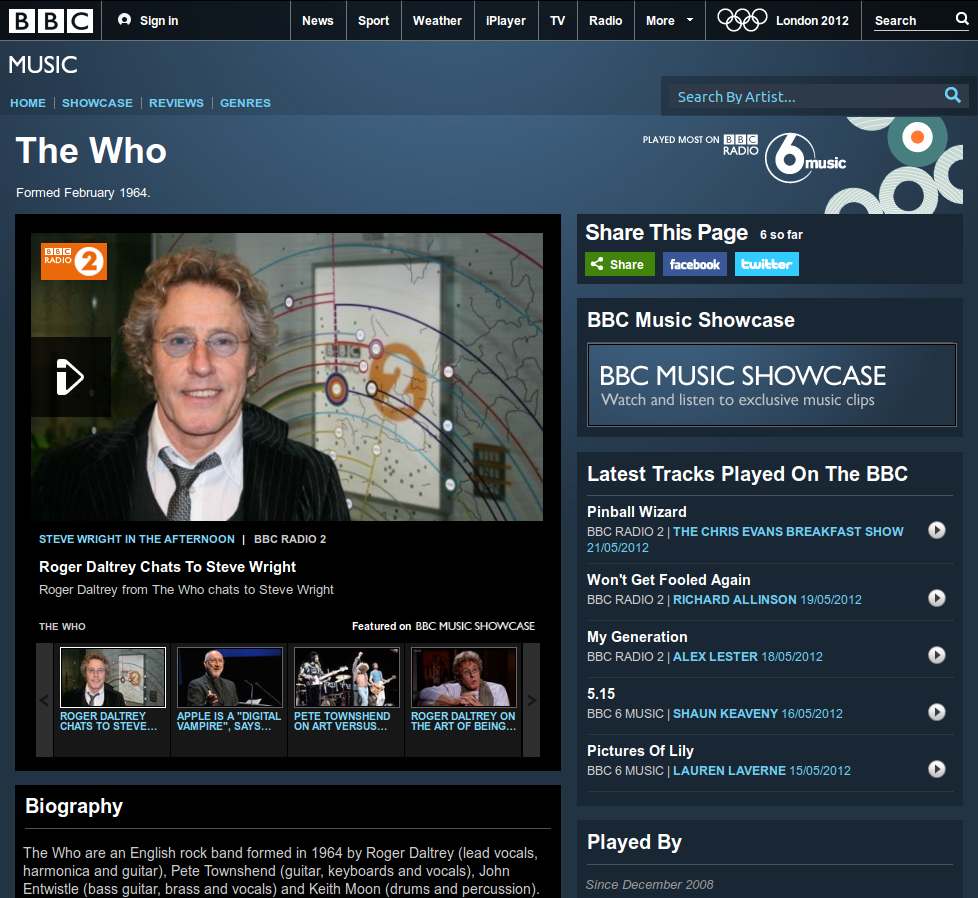
The Music Ontology
- Community-driven ontology for music-related data, first published in 2006
- Deals with editorial data, production workflow data, segmentation data
- Based on an event-based meta-model
- Used within Musicbrainz, Universal Music artist pages, BBC Music, Britten Thematic Catalogue...
Problem
If these ontologies are such a fundamental building block for our websites:
- How can we evaluate how "good" those ontologies are?
- Can such an evaluation be integrated within our development workflow?
- How can we identify possible ontology improvements?
What is "good"?
How well would a system backed by the evaluated ontology handle real-world user information needs?
e.g. "Who composed 'Peter Grimes'?"
Evaluation methodology
- Construct a dataset of verbalised user needs
- Extract recurrent patterns used to describe the information needs and associated frequencies
- Quantify how much of those patterns can be expressed within the evaluated ontology ("ontology fit")
Both task-based [Porzel2004] and data-driven [Brewster2004]
Ontology fit (1)
Who composed 'Peter Grimes'?
Ontology fit (2)
Ontology fit (3)
Who composed "Peter Grimes"?
Ontology fit: 1
Ontology fit (4)
What was the name of the artist who was on the cover of that magazine?
Ontology fit (5)
Ontology fit (6)
What was [the name of the artist] who was [on the cover of that magazine]?
Ontology fit: 0.5
Use-case: evaluation of the Music Ontology framework
Casual users
Evaluation against previous studies of user needs
Two previous studies:
- [Bainbridge2003], 502 queries from Google Answers, ontology fit: 0.828
- [Lee2007], 566 queries from Google Answers, ontology fit: 0.975
Evaluation on a dataset of verbalised user needs
- Google Answers archive in the music category, 3318 queries
- Yahoo! Answers, 4805 queries
- = 8123 music-related queries
Manual evaluation
On a random subset of the dataset (0.5%):
- Extract recurrent patterns (e.g. name(Person, Name)) and frequencies
- Compute ontology fit: 0.749
Evaluation at the lexical level (1)
Evaluation at the lexical level (2)
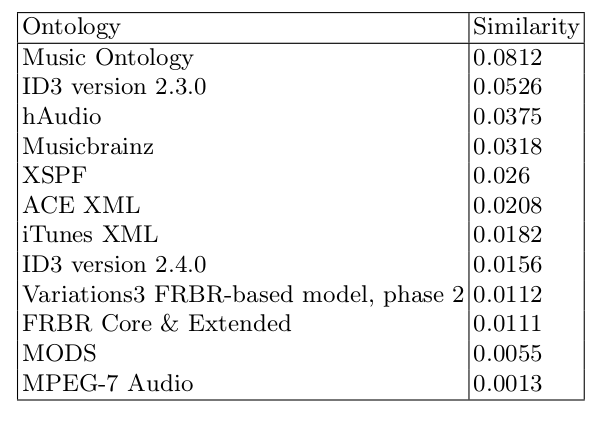
Evaluation at the lexical level (3)
- An ontology will score high if the terms used by users match the terms used in the ontology
- e.g. "Who composed 'Peter Grimes'" vs. "Who wrote 'Peter Grimes'"
- Can we cluster 'composed' and 'wrote' together?
Evaluation at the conceptual level
- Latent Dirichlet Allocation
- Each query is modelled as a finite mixture over an underlying set of topics
- We are trying to get to that underlying set of topics
- Using Gibbs sampling for parameter estimation and inference
Example inferred topics

Resulting ontology fit: 0.723
Users of music libraries
Manual evaluation
- Lack of datasets for music library logs
- Using reference queries captured in [Sugimoto2007]
- Manual analysis and evaluation, as above
- Ontology fit: 0.789
Discussion
Main features not expressible within the Music Ontology
- Uncertainty
- Partial characterisation of lyrics
- Emotions
- Description of the content of related media (e.g. music video)
- Other cultural aspects (e.g. position of track in charts)
Towards continuous evaluation?
- Trade-off between size of dataset, automation, and accuracy
- However, similar ontology fit measures were obtained for all combinations tried
- Feasible to plug ontology evaluation in a completely automated development and publishing workflow
Future work
- Integrate other aspects of the ontology in the evaluation measure, e.g. verbosity
- Apply to other domains
- Continuously refine ontologies written by domain experts to capture evolving domain data (e.g. News)
- Explore the use of Correlated Topic Models to estimate property coverage as well as concept coverage
Thank you!